In a previous subtopic, you learnt how to create codes using language data types, operators and expressions. These are important in writing the instructions and commands for your app to perform its intended task. Aside from these, you can also use algorithms in coding.
Algorithms are steps or rules for solving a specific problem or accomplishing a specific task. They provide a clear and systematic approach to problem-solving. Likewise, they outline the necessary actions and instructions to achieve a desired outcome.
In creating an application, you should learn about these standard programming algorithms. They are well-defined algorithms widely accepted in programming. These algorithms are proven effective in solving specific problems or performing common tasks. The standard programming algorithms can include the following:
- Sorting algorithms
- Searching algorithms
- Graph algorithms
Using these algorithms when coding provides the most optimal solution for a problem. They have been refined over time and are generally well-tested. This reduces the likelihood of errors or bugs. Moreover, using these promotes code reusability and maintainability. Instead of figuring out a way to accomplish tasks, you can use existing algorithms to save time and effort.
Every day, you follow steps to perform most of your daily tasks. You have schedules to follow from when you wake up in the morning until you go to bed at night. These steps are vital for you to function.
The same principle applies to algorithms. As you previously learnt, algorithms are steps or rules for solving a specific problem or doing a specific task. You can rely on standard algorithms tried and tested by experts. These algorithms let you build reliable and optimised software without starting from scratch.
Algorithms define the program's logic and structure of the program. They determine how you process data, decide and get results. Using well-designed algorithms can ensure your app performs its function accurately and efficiently. They help smoothen the process by providing clear steps and enabling code reuse. You can develop algorithms using the following constructs:
Sequence constructs
In using sequence constructs to create algorithms, you can use the sequential execution flow. The sequential execution flow refers to the order in which statements are executed in a program. Here, each statement is linearly executed one after another. It implies that the program starts from the beginning and progresses through each statement until the end.
Creating algorithms using sequence constructs involves designing a step-by-step procedure. This procedure aims to solve a problem or perform a task. Here are the steps you can follow in developing algorithms using sequence constructs:
- Clearly understand and define the problem or task you want to solve with the algorithm.
- Determine the inputs the algorithm needs and the expected outputs it should produce.
- Break down the problem or task into smaller subtasks or steps. Each step should be a self-contained action that contributes to the overall solution.
- Determine the sequence in which the steps should be executed. This establishes the sequential flow of the algorithm.
- Identify the necessary variables to store and manipulate data within the algorithm. You learnt these variables in a previous subtopic.
- Express the steps and their sequence in a formalised and structured manner. You can use pseudocode or a programming language.
- Test the algorithm with different inputs and confirm that it produces the expected outputs. Then, refine and debug the algorithm as needed.
Examples
Here are some examples of algorithm development using sequence constructs:
Calculating the sum of numbers
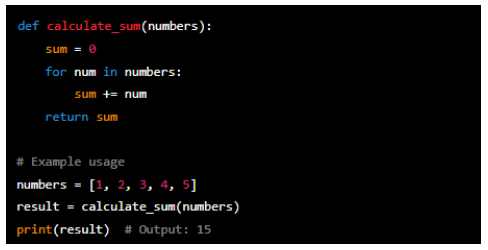
In this example, the algorithm takes a list of numbers as input. It initialises a variable 'sum' to 0 and then iterates through each number in the list. Then it adds each number to the 'sum' variable, accumulating the total sum. Finally, it returns the sum as the result.
Reversing a string
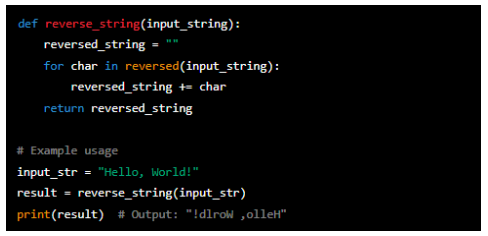
This algorithm takes a string as input. It initialises an empty string variable 'reversed_string'. Then, it repeats through each character in the input string in reverse order using the 'reversed()' function. It adds each character to the 'reversed_string' variable. Finally, it returns the reversed string.
Selection constructs
In using selection constructs to create algorithms, you can use the conditional execution flow. The conditional execution flow is the ability of a program to decide and execute different code blocks. It is also known as control flow. These codes are based on certain conditions. It allows for branching in the program's execution based on evaluating logical expressions. To develop algorithms using selection constructs, here are the steps you can follow:
- Determine the specific condition or criteria the program needs to decide.
- Choose the appropriate selection construct to create the branching structure in your algorithm. You learnt these constructs in a previous subtopic.
- Write the code blocks that will be executed based on the condition's evaluation. This includes the code to be performed when the condition is true and the code to be used when the condition is false.
- Test the algorithm using different inputs and check its correctness. If necessary, refine the algorithm by adjusting the conditions or code blocks to achieve the desired behaviour.
- Consider any special or edge cases needing specific handling. You should modify the algorithm accordingly.
- Provide clear and concise documentation for the algorithm. It can include the following:
- explanation of the condition
- the expected behaviour
- assumptions made
Examples
Here are some examples of algorithm development using selection constructs:
Checking if a number is even or odd
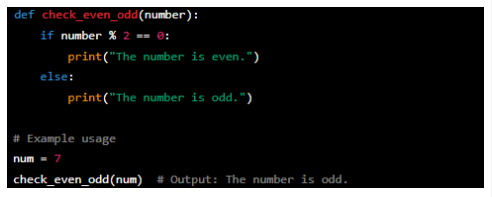
The algorithm in the snippet takes a number as input and uses an if-else statement to check if it is even or odd. The condition 'number % 2 == 0' checks if the number is divisible by two without a remainder. If true, it prints that the number is even. Otherwise, it prints that the number is odd.
Finding the maximum of two numbers
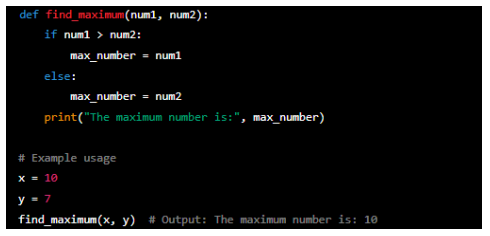
This algorithm takes two numbers as input and uses an if-else statement to compare them. If 'num1' is greater than 'num2', it assigns 'num1' as the 'maximum' number. Otherwise, it assigns 'num2'. The algorithm prints the maximum number.
Iteration constructs
In using iteration constructs to create algorithms, you can use the repetitive execution flow. Repetitive execution flow allows a code section to be executed repeatedly based on a certain condition. It is also known as iteration or looping. Moreover, it is useful when you perform a task many times or iterate over a collection of items.
Iteration constructs are crucial in enhancing the efficiency and optimisation of complex algorithms. These constructs allow for the repeated execution of a block of code, making them invaluable for the following:

Iteration constructs can avoid duplicating code, leading to more compact and manageable code. This not only makes the code easier to understand and maintain but also reduces the chances of errors that might arise from repeated coding. You can also avoid the overhead of writing multiple times. This not only minimises memory usage but also leads to more efficient use.
Complex algorithms often need fine-tuning as new data is encountered or as the algorithm evolves. Iteration constructs provide an adaptable framework for handling changing conditions. This allows developers to change the algorithm's behaviour with minimal effort.
Develop algorithms using iteration constructs
To develop algorithms using iteration constructs, you can follow these steps:
- Determine the specific task or operation that you must repeat. Likewise, identify the condition that will determine when to stop the repetition.
- Select the suitable iteration construct for your algorithm. This should be based on the nature of the repetition requirement. You learnt these constructs in a previous subtopic.
- Specify the condition that determines whether the loop should continue or end. This condition will be evaluated before each iteration.
- Define the instructions or actions to be executed within the loop. This code block will be repeated until the loop condition evaluates to false.
- Test the algorithm using different inputs and verify that the repetition occurs as intended. If necessary, refine the algorithm by adjusting the loop condition or the code within the loop body.
- Consider any special scenarios or edge cases that may affect the repetition requirement. You should handle them appropriately within the algorithm.
- Provide clear documentation for the algorithm. This can include the following information:
- explanation of the repetition requirement
- expected behaviour
- assumptions made
- special considerations
Examples
Here are some examples of algorithm development using iteration constructs:
While loop (Python)
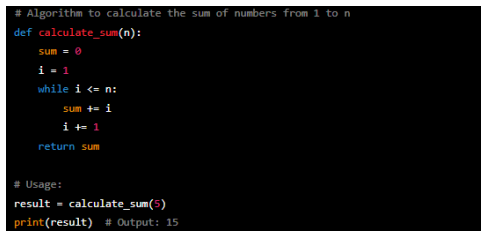
This algorithm uses a while loop to calculate the sum of numbers from one to n. The loop starts with an initial value of 'i' equal to one and continues iterating until 'i' becomes greater than 'n'. Inside the loop, the current value of 'i' is added to the 'sum', and 'i' is increased by one in each iteration.
For loop (JavaScript)
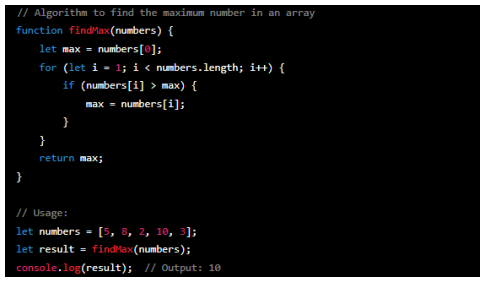
This algorithm uses a for loop to iterate over an array of numbers and find the maximum value. The loop initialises the variable 'i' to one and continues until 'i' is less than the array's length. Inside the loop, it compares each array's element with the current maximum 'max' value. It updates the' max' value if an element exceeds the current maximum.
Do-while loop (C++)
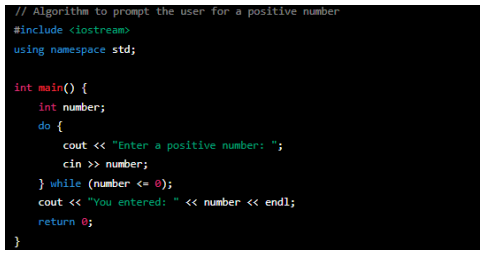
This algorithm uses a do-while loop to stimulate the user to enter a positive number repeatedly. The loop executes at least once because the condition is evaluated at the end of each iteration. If the user enters a non-positive number, the loop continues prompting for input until a positive number is provided. Once a positive number is entered, the loop ends, and the program displays the entered number. This example also shows user interaction in the algorithm or creates a separate heading for user interaction.

Aside from developing algorithms, you should also know how to create and use data structures. Data structures are containers that allow you to organise, store and manipulate data efficiently. They provide a way to represent and manage data in a structured manner. This enables easy data access, modification and traversal.
The concepts of declaration and initialisation of variables are crucial in data structures. Declaration refers to specifying the type and name of a variable without assigning it a value. It informs the compiler or interpreter about the existence and type of the variable. On the other hand, initialisation involves assigning an initial value to a declared variable. It sets the initial state of the variable and allows it to be used in computations and operations.
Data structures optimise data storage and processing. They let you search, insert, delete and change data easily. Choosing the right data structure can lead to more efficient solutions to coding problems. These structures provide high-level interfaces and operations, allowing you to focus on solving problems. The basic data structures include the following:
Arrays
An array is a set of elements of the same data type stored at contiguous memory locations. It provides a way to store and access many elements using a single variable. It has a fixed size and allow random access to elements using an index. Moreover, an array can be one-dimensional or multi-dimensional. Here is an example:

This code declares an array named ‘numbers’ that stores a sequence of integers. The array is initialised with the values ‘1, 2, 3, 4, 5’.
Arrays are commonly used for the following tasks:
- Storing lists of items
- Implementing matrices
- Handling large amounts of data
- Representing ordered collections
Lists
Lists are dynamic data structures that can store elements of different data types and can grow or shrink in size. On the other hand, an array list is a specific implementation of lists in some programming languages like Java. It provides resizable arrays and offer operations for adding, removing and accessing elements. An array list is one way to implement a list. Here is an example:
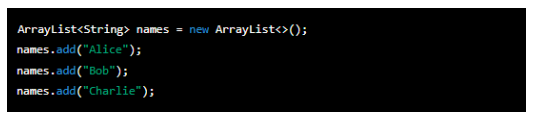
This code creates an ArrayList named 'names' to store strings. It then adds three names to the list: 'Alice', 'Bob' and 'Charlie'.
Lists are used for the following tasks:
- Managing dynamic collections of data
- Implementing data structures like stacks and queues
- Implementing algorithms like sorting and searching
- Representing data in a structured format aiding in data display
Dictionaries and maps
Dictionaries and maps are key-value pair data structures. They allow efficient retrieval of values based on their associated keys. However, they provide a way to store and access data using unique keys. You can perform fast lookup operations for retrieving values based on keys. These can include HashMap, hash table or associative arrays. Moreover, these are not limited to hash maps or associative arrays. Depending on the programming language or context, you can use different data structures. Here is an example:
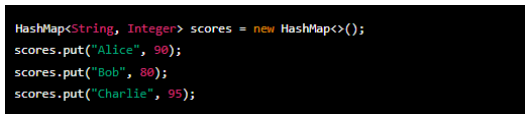
This code creates a HashMap named 'scores'. The map associates names (strings) with corresponding scores (integers). It adds three entries to the map:
- 'Alice' with a score of 90
- 'Bob' with a score of 80
- 'Charlie' with a score of 95
Dictionaries or maps are used for the following tasks:
- Indexing and searching data
- Storing and saving structure settings
- Applying caches
- Assisting efficient data retrieval
Sets
A set is a group of unique elements with no particular order. They enforce uniqueness. It means they cannot contain duplicate elements. Likewise, they provide operations for set operations like union, intersection and difference. Sets can include a hash set, tree set or linked hash set. Here is an example:

This code creates a HashSet named 'numbers' to store unique integers. It adds three numbers to the set: 1, 2 and 3. Duplicate values are automatically removed.
Sets are used for the following tasks:
- removing duplicates from a collection
- checking for the presence of an element
- implementing mathematical set operationsw
- eliminating ordering in scenarios where order does not matter
Stacks and queues
Stack is a data structure that tracks the 'last-in-first-out' or LIFO principle. On the other hand, a queue refers to the first-in-first-out or FIFO principle. Stacks allow adding and removing elements from the top. On the other hand, queues allow adding elements at the rear and removing elements from the front. Here is an example:
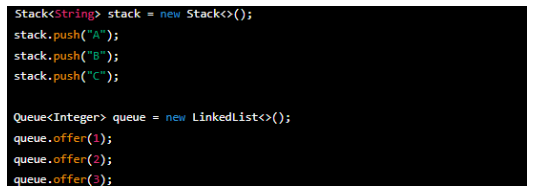
This code shows a stack and a queue. The stack named 'stack' uses the 'push() method' to add elements 'A', 'B' and 'C' to the top. The queue named 'queue' uses the 'offer() method' to add elements '1, 2 and 3' to the end of the queue.
The push() method adds elements to the top of the stack. It pushes the given element onto the stack, making it the new top element. On the other hand, the offer() method adds elements to the end of the queue. It offers the given element to the queue, placing it at the end.
Stacks are used for the following tasks:
- Function call management
- Expression evaluation
- Undo/redo operations
On the other hand, queues are used for the following tasks:
- Scheduling
- Managing waiting lines
- Handling message passing
Trees
A tree is a hierarchical data structure formed from nodes that have parent–child relationships. They represent hierarchical relationships between elements.
A node is a basic building block of various hierarchical structures. It represents an individual element within a larger structure and contains some data. Likewise, it consists of the following:
- The root node is the highest node of a tree or a graph. It is the starting point from which all other nodes are derived. In a tree, there is only one root node. It does not have any parent nodes. The root node is typically the entry point for accessing the tree or graph structure.
- Internal nodes or non-leaf nodes are between the root and leaf nodes. These nodes have at least one child node but are not themselves the leaf nodes. In other words, internal nodes have descendants but are not the ultimate endpoints of any branch.
- Leaf nodes or terminal nodes do not have child nodes. They are the endpoints of the structure's branches or paths and do not have any further descendants. Leaf nodes often represent the structure's final or individual elements or data points.
Trees can be binary or have many child nodes. Binary nodes can have at most two child nodes. This means that each node in a binary tree can have either zero, one or two child nodes. On the other hand, multiple child nodes can have more than two child nodes. Here is an example:

This code creates a binary search tree (BST) named 'bst' that stores integers. It inserts three nodes into the BST with values 50, 30 and 70.
Trees are used for the following tasks:
- Organising hierarchical data
- Implementing efficient search and retrieval algorithms
- Representing file systems and directories
- Representing data for various graph algorithms
Graphs
A graph is a set of nodes connected by edges. They represent relationships between elements. They can be directed or undirected. Directed graphs mean they have a specific direction. Graphs can have cycles or be acyclic.
A cyclic graph travels along a sequence of edges and returns to the starting point. This creates a loop or cycle within the graph. On the other hand, an acyclic graph is a graph that does not contain any cycles. This means no closed loops or paths that return to the starting point.
Here is an example:

This code creates a graph named 'graph' and adds three edges: 'A-B', 'A-C' and 'B-C'. The edges connect the nodes 'A', 'B' and 'C'. Graphs are used for the following task:
- modelling networks
- representing social connections
- solving pathfinding problems
- implementing graph algorithms
Create data structures
To create data structures, you can follow these steps:
- Understand the exact needs of your application and determine the data that needs to be stored and manipulated.
- Choose appropriate data structures based on the requirements. You must choose a data structure that can efficiently represent and handle the data. Consider factors like the type of data, access patterns and operations you will perform.
- Define your chosen data structures. You must determine the fields each data structure element will have and how they are related.
- Implement the chosen data structures in your language. Create the necessary classes, structs or objects to represent the data structure. They provide operations to manipulate and access the data.
- Test the data structures thoroughly to ensure they behave as expected. You should use various test cases to verify their correctness, performance and handling of edge cases. Debug any issues that arise during testing.
After creating these data structures, you can use them in programming. To use these data structures, you can follow these steps:
You should identify the specific operations or computations that you should perform
You should identify the relationships between the data and how you can access or modify them.
It may involve inserting, deleting, updating or retrieving elements from the data structures
This may involve the following:
- accepting user input
- reading data from files or databases
- presenting the results
You will learn more about these test cases in the succeeding subtopic.
Watch
You can watch this video to learn more about the data structures and algorithms:
In a previous subtopic, you learnt about developing algorithms using sequential constructs. You can use these algorithms to code sequential access algorithms. These algorithms use sequential constructs to systematically and organically process data.
Sequential access algorithmsrefer to sequentially accessing data records in a predefined order. These algorithms are commonly used when handling data from text files. Text file handling involves reading and writing data from and to text files. Text filesstore and exchange data in a human-readable format. They contain plain text organised in lines or records. Moreover, text file handling allows apps to interact with text files. They read their contents, modify data or create new files.
These algorithms are essential for reading and writing text files. They enable the processing of data sequentially. When reading a text file, they read each line or record one by one, allowing for processing, analysis or extraction of relevant data. Similarly, when writing to a text file, they write data sequentially, ensuring it is stored in the desired order.
They provide structured and controlled access to the file's content. Sequential access algorithms allow for efficient and organised reading or writing of data. This ensures the compiler processes the data correctly.
When using these standard algorithms in file handling, you must know the file input and output operations. File input and output operations involve several actions, including:
- opening a file
- reading data
- writing data
- closing the file
- appending data
The process typically starts with opening a file, specifying the file's path and the desired mode. These modes can include read, write or append. Once the file is opened, the sequential access algorithm can perform reading or writing operations. You can use the appropriate functions in your language. Finally, the file is closed to release system resources and ensure data integrity.
When working with text files, you should understand the process of opening and closing files. Opening a text file involves specifying the file's path and the desired mode of operation, which can be reading, writing or appending data. Once you open the file, you can perform operations like reading from or writing to the file.
To open a text file, you can use a function from your programming language. It takes two parameters: the file path and the mode.
Examples
Here are examples of opening a file using standard sequential access algorithms in various languages:
Python

This function 'open_file_python' takes a 'filename' as input and opens the file in read mode using the 'open()' function. The 'with' statement ensures that the file is automatically closed after reading. The file content is then read using the 'read()' method and stored in the 'content' variable. Finally, the function returns the content of the file.
JavaScript
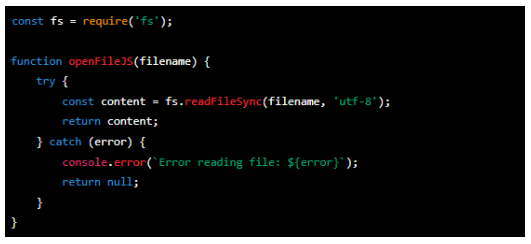
This function 'openFileJS' takes a 'filename' as input. It uses the 'fs' module, a built-in module in Node.js, to read the file synchronously using the 'readFileSync()' method. The file content is returned if read successfully. If there is an error, it is caught and noted to the console.
C++
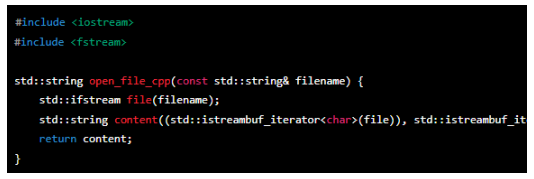
This C++ function 'open_file_cpp' takes a 'filename' as input and creates an 'ifstream' object to open the file for reading. The file content is read using the constructor of the 'std::string' class, which takes two iterators to read the file content into a string. Finally, the function returns the content of the file.
File handling modes
Once you have opened the file, you can determine the file handling mode you will use. File handling modes determine the operations you can perform on a text file. These can include the following:
Read mode ('r')
Reading a text file refers to accessing and retrieving the file contents that contain plain text. When you read a text file, you typically open it, read its contents and perform operations or extract data from the text data. This can involve the following:
- reading it line by line
- reading it character by character
- reading it in larger chunks
This depends on the requirements of your program or the file structure. To code standard sequential access algorithms used in reading text files, you can follow these steps:
- Use your programming language's appropriate function or method to open the text file. This typically involves specifying the file name or path and the desired access mode.
- Use the appropriate function to read the contents of the file. This can be done line by line, character by character or in larger chunks. Here are some examples:
Programming Language Functions to Read the Contents of the File C++ ‘ifstream’: This class in C++ allows reading data from files using various member functions like ‘getline()’ and ‘get()’.
‘fopen’: This is a C-style file-handling function to open a file and read its content.
JavaScript ‘fs.readFile()’: This is an asynchronous file read function in Node.js for reading file contents.
‘fs.readFileSync()’: This is the synchronous version of fs.readFile().
Python ‘open()’: This is a built-in Python function to open a file for reading.
read()’: This is a method to read the entire contents of the file at once.
‘readline()’: This is a method to read a single line from the file.
‘readlines()’: This is a method to read all lines from the file into a list.
- Once you have read the file's contents, you can process the data as needed. This can involve the following:
- parsing the text
- extracting relevant information
- performing calculations
- doing manipulations
- Here is an example of coding standard sequential access algorithms used in reading text files:
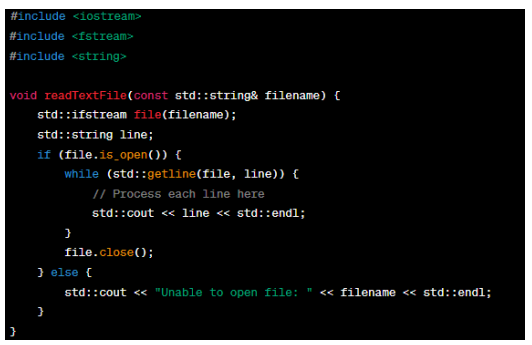
This C++ function 'readTextFile' takes a 'filename' as input and creates an 'ifstream' object to open the file for reading. It then reads each line from the file using the 'std::getline()' function in a 'while' loop and processes each line as desired. In this example, it prints each line. If the file cannot be opened, it displays an error message.
While the general steps are similar, the specific functions used to perform these steps may vary. You must consult the documentation for the programming language to understand its syntax.
Write mode ('w')
Writing a text file refers to creating or modifying it by adding or replacing its contents with new data. When you write in a text file, you essentially save information from your program or application to a file on disk. To code standard sequential access algorithms used in writing text files, you can follow these steps:
- Use the appropriate function from your programming language to open the text file. You should specify the file name or path and the desired file access mode.
- Use the appropriate function or method to write data in the file. This can involve the following:
- Writing individual lines of text
- Writing specific data values
- Writing larger chunks of information
This can depend on your program's requirements. Here are some examples:
| Programming Language | Functions to Read the Contents of the File |
|---|---|
| C++ |
‘ofstream’: This class in C++ allows writing data to files using various member functions like write() and put(). ‘fopen()’: This is the C-style file handling function to open a file and write its contents. |
| JavaScript |
fs.writeFile()’: This is the asynchronous file write function in Node.js for writing in a file. ‘fs.writeFileSync()’: This is the synchronous version of fs.writeFile(). |
| Python |
‘write()’: This is the method to write data in the file. ‘writelines()’: This is the method to write a list of lines in the file. |
Writing in a text file allows you to store and persist data that can be later retrieved, processed or shared with other apps. It is commonly used in various scenarios, such as:
- Saving configuration settings
- Logging program events
- Generating reports
- Creating data backups
Here is an example:
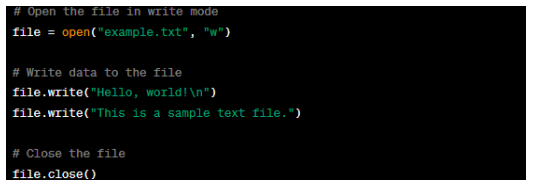
In Python, you can open a text file using the 'open()' function with the file name and the 'w' model object to indicate writing. Use the file object's 'write()' method to write data on the file. After writing, it is important to close the file using the 'close()' method to ensure the changes are saved.
While the general steps are similar, the specific functions used to perform these steps may vary. You must consult the documentation for the programming language to understand its syntax.
Append mode ('a')
Appending a text file means adding new content or data to an existing file without overwriting the current content. When you append to a file, the new data is added at the end, preserving the existing content.
Appending is useful when adding new information to a file without losing any previously stored data. It allows you to update and expand the file content continuously over time.
The steps may vary depending on your programming language, but the general concept remains the same. Here are the steps you can follow:
- Use the appropriate file handling mode to open the file in append mode. This allows you to add new content to the existing file without overwriting the previous content.
- If necessary, position the file pointer at the end of the file to ensure that the new content is appended at the correct location.
- Use the appropriate file writing function or method to write the new content to the file. This can be done line by line or in any desired format.
Here is an example:

In this example, the 'write()' method of the file object is used to add new content to the file. Each call to 'write()' adds a new line of text to the file. The example includes the newline character '\n' at the end of each line to ensure proper line breaks.
While the general steps are similar, the specific functions used to perform these steps may vary. You must consult the documentation for the programming language to understand its syntax.
Closing a text file
Finally, you must close the file to release system resources and ensure data integrity. Closing a text file means ending the connection between the program and the file. You release any system resources associated with it and ensure any changes made to the file are saved. When you close a file, you cannot access or modify it further. To close a text file, here are the steps you can follow:
- Ensure you have a reference or handle to the open file you want to close.
- Invoke the close operation or method from the programming language or file input/output (I/O) library to close the file. This operation typically takes no parameters.
- Check for any errors that may occur during the file-closing process. Error-handling mechanisms, such as error codes, can be used to handle and report any issues. Here is an example:
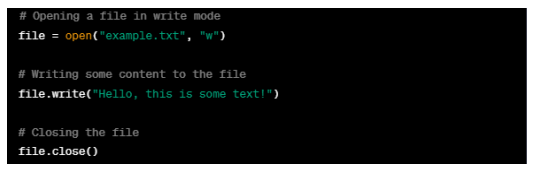
In this example, a file named 'example.txt' is opened in write mode using the 'open()' function with the 'w' parameter. Then the 'write()' method is used to write the string 'Hello, this is some text!' to the file. Finally, the file closes using the 'close()' method. It is essential to close the file after writing to ensure that all the data is properly saved and that the file's resources are released.
Closing a file is essential to maintain the integrity of the file system and free up system resources. Failing to close a file properly may result in data corruption, loss or unpredictable behaviour.

Aside from algorithms and data structures, you should also learn about string manipulation. It is significant in coding using standard programming algorithms. String manipulation refers to modifying, extracting or manipulating strings. It involves performing various operations on strings, such as:
- searching
- replacing
- concatenating
- parsing
- formatting
You learnt about strings in the previous subtopic. These are sequences of characters. String manipulation allows you to extract relevant data from strings and modify their content. Moreover, you can format them in specific ways to meet the algorithm requirements. It enables you to extract substrings, separate data elements and analyse patterns within the text. String manipulation is also often used to format strings for display or output. It allows you to create well-formatted output messages, reports or user interfaces.
Here are the common string manipulation techniques that you can apply:
String concatenation
String concatenation refers to combining two or more strings into a single string. You can achieve this in most languages using the concatenation operator (+). Likewise, you can use specific string interpolation or formatting methods. Here is an example of using the concatenation operator in Python:
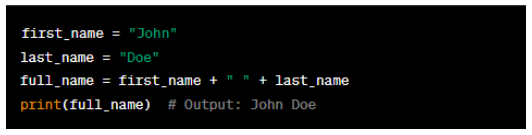
In this example, two string variables, 'first_name' and 'last_name', are declared and assigned values. The '+' operator concatenates these two strings with a space between them. The result is stored in the 'full_name' variable. Finally, the 'print()' function displays the concatenated full name.
String length and accessing characters
Determining the length of a string allows you to know the number of characters it contains. Accessing individual characters in a string is essential for various string manipulation tasks. In many languages, strings are zero-indexed, meaning the first character is at index 0. Here is an example of using string length and accessing characters in JavaScript:
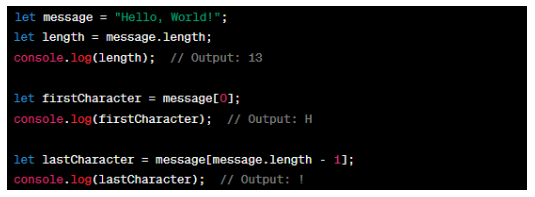
In this example, a string variable 'message' is declared and assigned a value. The '.length' property is used to determine the length of the string, which is then printed to the console. To access individual characters, square brackets ([]) are used along with the index of the character. In this case, the first character is accessed using index '0', and the last character is accessed using the length of the string minus one.
Changing case and capitalisation
String manipulation often involves changing the case of strings. This includes converting strings to uppercase or lowercase. This can include capitalising the first letter of a string or modifying the case of specific characters or substrings. Here is an example in JavaScript:
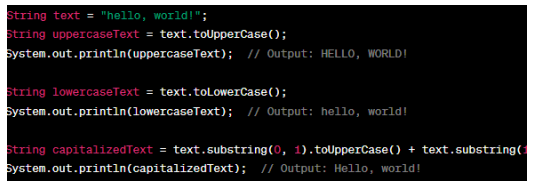
In this example, a string variable 'text' is declared and assigned a value. The '.toUpperCase()' method converts the entire string to uppercase, and the result is stored in the 'uppercaseText' variable. Similarly, the '.toLowerCase()' method converts the string to lowercase. The 'substring()' method extracts the first character to capitalise the first letter of the string. This is converted to uppercase using the '.toUpperCase()' method. The remaining characters are obtained using the 'substring()' method starting from index '1'. They are concatenated with the capitalised first letter to form the 'capitalizedText'. The results are printed to the console.
Searching and finding substrings
This string manipulation technique involves the following operations:
- searching for a specific substring
- finding the index of a substring
- replacing substrings within a string
These are useful when working with text data and manipulating strings based on specific patterns or criteria. Here is an example in Python:
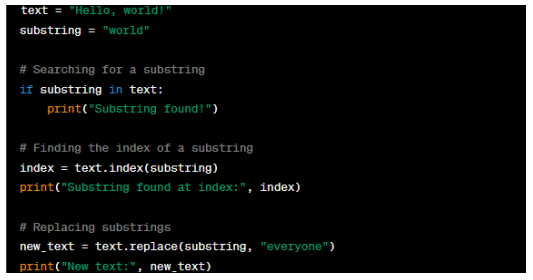
In the example, we have a string variable 'text' with the value 'Hello, world!' and a substring variable 'substring' with the value 'world'. We use the 'in' operator to check whether the 'substring' is in the 'text' string. The 'index' method returns the index at which the 'substring' is found in the 'text' string. The 'replace' method replaces occurrences of the 'substring' with a specified replacement string. This creates a new string.
Splitting and joining strings
This technique involves dividing strings into many substrings based on a delimiter. This results in a list of substrings. On the other hand, joining strings combines many strings into a single string using a separator or delimiter. Here is an example in JavaScript:
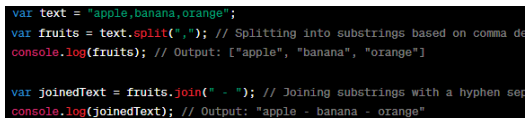
The example shows the ‘split' method of splitting a string into substrings. The 'split' method splits the 'text' string into substrings based on the comma delimiter (,) and returns an array of substrings. In the joining example, the 'join' method concatenates the elements of the 'fruits' array into a single string, separated by a hyphen (-).
Trimming and padding strings
Trimming involves removing leading and trailing whitespace characters from a string. On the other hand, padding involves adding whitespace or specific characters to the beginning or end of a string. These achieve a desired length or format. Here is an example in JavaScript:
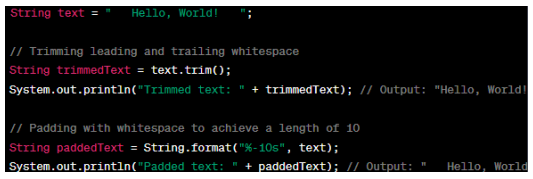
The 'trim' method removes leading and tracing whitespace from the 'text' string, resulting in the trimmed text. In the padding example, the 'String.format' method pads the 'text' string with whitespace to achieve a length of 10 characters. The '%' symbol specifies the format, and the '-10s' format specifier means left-justified with a width of 10 characters.
String comparison and sorting
String comparison involves comparing strings for equality or order. Sorting strings means arranging the strings. This can be done alphabetically or based on specific criteria. These are also common operations when working with collections of strings. Here is an example in Python:
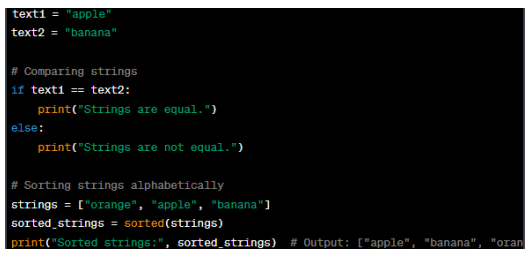
The example compares two strings, 'text1' and 'text2', using the '==' operator to check for equality. The 'sorted' function sorts a list of strings, 'strings', in alphabetical order. The sorted strings are stored in the 'sorted_strings' variable.
The string manipulation techniques are generally similar across languages. However, there can be some differences in syntax and available functions. It is always best to refer to the language's documentation for more detailed and updated information.
Apply string manipulation
To apply string manipulation, you can follow these steps:
- Determine the specific string manipulation techniques you should perform in your application.
- Select a language that provides robust string manipulation capabilities. This language must suit your application's requirements.
- Familiarise yourself with the string manipulation functions and methods from the language. You can read the language's documentation. These functions and methods can help you learn about the available string manipulation techniques.
- Determine the order in which you must apply the string manipulation techniques. You should consider any dependencies between different manipulation tasks.
- Implement the string manipulation operations in your application's code. You should use the appropriate functions, methods and syntax in your language. These will perform the desired string manipulations.
- Execute your code and test it with different input values to ensure the string manipulations work correctly. You should debug any issues or errors that arise during testing.
- Review your code and identify areas where you can improve the strings. You should look for opportunities to reduce redundancy. Likewise, look for opportunities to enhance performance or maintain the code.
Quiz
